

Аналитики часто решают нестандартные задачи с помощью нестандартных методов. В итоге код становится нагруженным, сложно читаемым и его сложно поддерживать. Чтобы упростить код и ускорить решение задачи, можно использовать оконные функции.
В этой статье мы разберёмся, что это такое, какие они бывают и как их использовать.
Что такое оконные функции в SQL
Оконные функции — это инструмент в работе аналитика, который позволяет выполнять вычисления налету внутри окна. Они используются для выполнения сложных вычислений без группировки данных в одну строку.
Для чего нужны оконные функции
Оконные функции сильно упрощают жизнь аналитиков. Они позволяют анализировать имеющуюся информацию без изменения существующей структуры.
Применение оконных функций преследует следующие цели:
- Ранжирование
- Бакетирование (создание групп данных)
- Смещение
- Агрегация
- Анализ
- Комбинация нескольких функций.
Как работают
При расчете, оконные функции делят данные на части (окна, партиции) по определенным столбцам и условиям. Внутри этих окон уже производится расчет в зависимости от выбранной функции.
Например, у нас есть таблица:
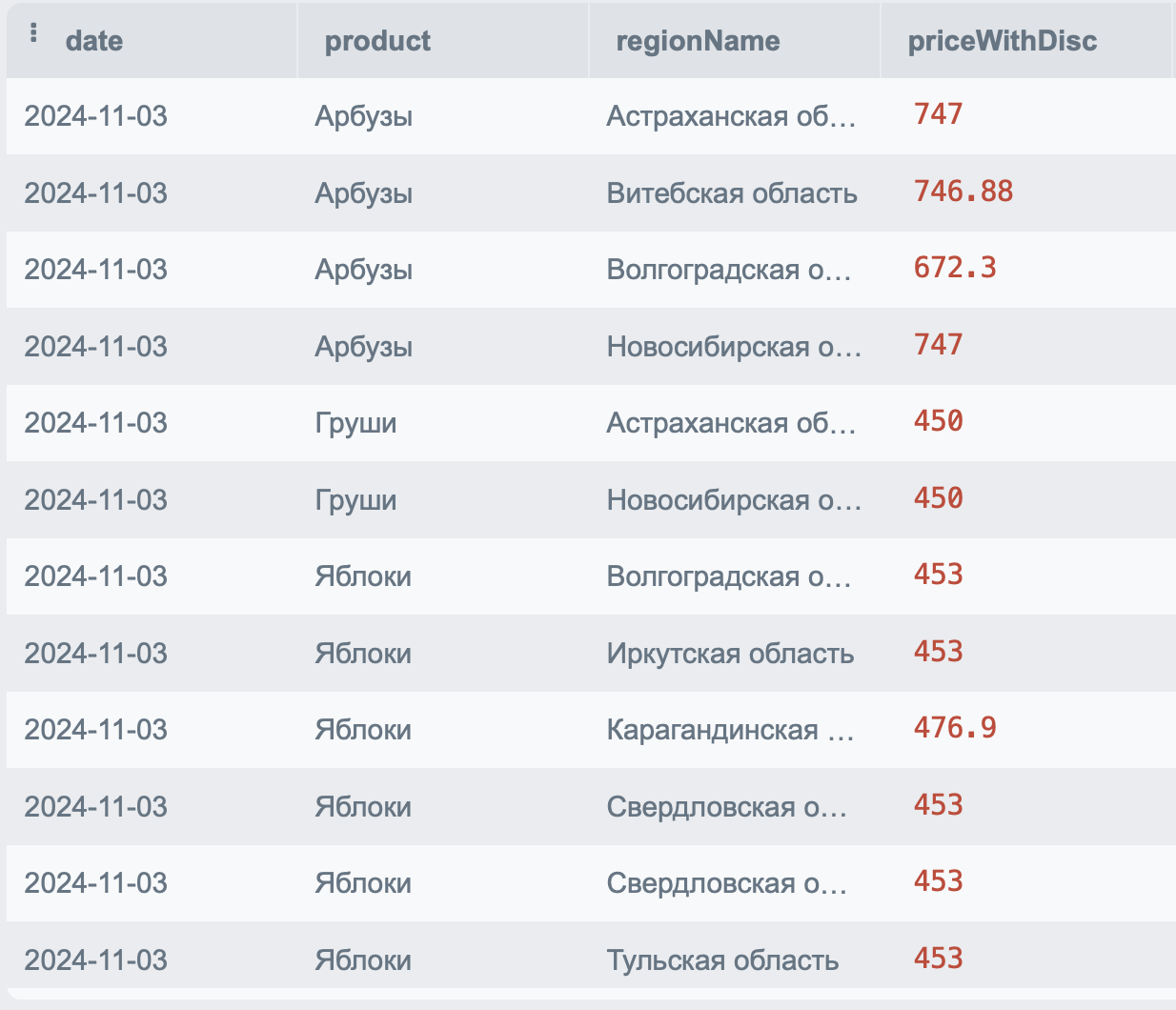
Для того чтобы посчитать количество продаж каждого продукта, мы можем написать оконную функцию вида:
SELECT p.*,
COUNT(product) OVER(PARTITION BY product) as CNT
FROM PRODUCT p
В результате мы получим следующее:
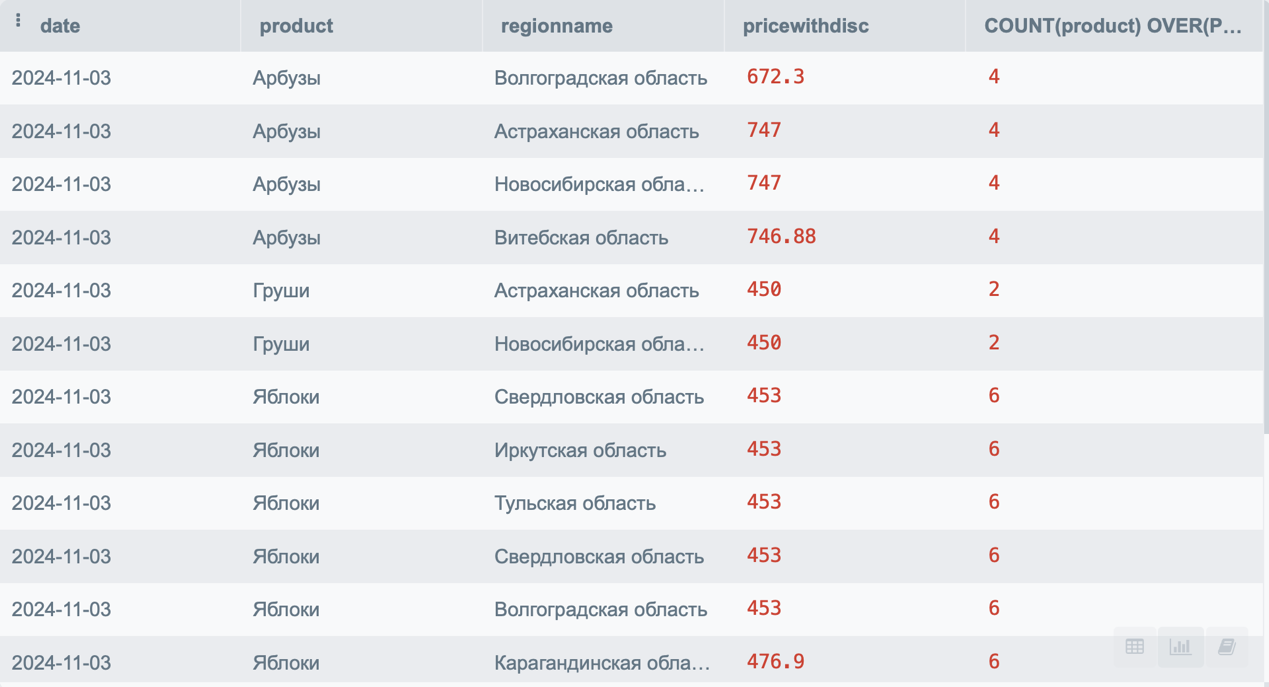
Как видите, структура данных осталась прежней, но мы получили суммарное количество каждого продукта.
Сразу поясню, что это можно сделать с помощью обычной агрегации с использованием GROUP BY, но это потребует больше итераций и снизит эффективность и читаемость кода.
Давайте сравним:
SELECT
p.*,
p1.CNT
FROM PRODUCT p
LEFT JOIN (SELECT product, COUNT(product) as cnt
FROM PRODUCT
GROUP BY product) p1 ON p.product = p1.product
Согласитесь, что оконная функция значительно упрощает чтение кода и выглядит изящно, по сравнению с подзапросом.
Синтаксис
Базово оконная функция выглядит следующим образом:
ФУНКЦИЯ(Столбец для вычислений) OVER(PARTITION BY столбец для партиции ORDER BY столбец для сортировки [ASC/DESC]).
Стоит отметить, что в ряде функций необходимо указывать PARTITION BY и можно не указывать ORDER BY, и наоборот. Например, в функции ROW_NUMBER() обязательно нужно указывать ORDER BY, иначе она не будет работать, но при этом можно не указывать PARTITION BY.
Дополнительно функции можно обогатить RANGE и ROW для ограничения количества строк в рамках группы.
Виды оконных функций
Как мы выяснили оконные функции позволяют анализировать имеющуюся информацию про помощи различных функций.
Выделяют следующие виды оконных функций:
- Агрегатные функции
- Функции ранжирования
- Функции смещения
- Индексные функции
- Аналитические функции
- Функции бакетирования
- Функции конкатенации
Агрегатные функции
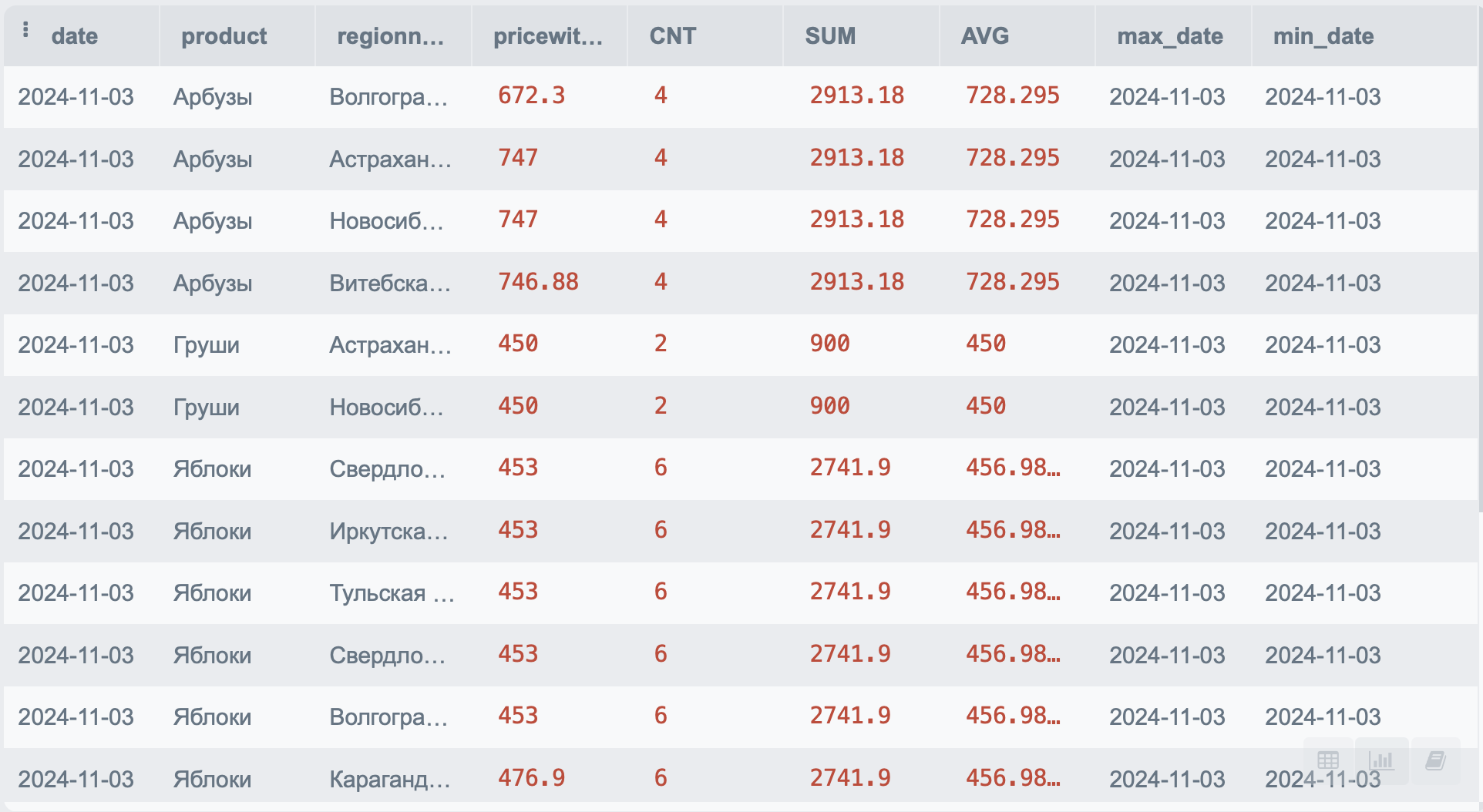
Агрегатные функции позволяют вычистить количество (COUNT), сумму (SUM), среднее значение (AVG), минимальное (MIN) и максимальное (MAX) значения.
В прошлом примере мы уже нашли количество продуктов, теперь давайте найдем остальные агрегатные функции.
Я объединю их все в один запрос:
SELECT p.*,
COUNT(product) OVER(PARTITION BY product) as CNT,
SUM(pricewithdisc) OVER(PARTITION BY product) as SUM,
AVG(pricewithdisc) OVER(PARTITION BY product) as AVG,
MAX(date) OVER(PARTITION BY product) as max_date,
MIN(date) OVER(PARTITION BY product) as min_date
FROM PRODUCT p
В результате выполнения запроса наша таблица будет выглядеть следующим образом:
Функции ранжирования
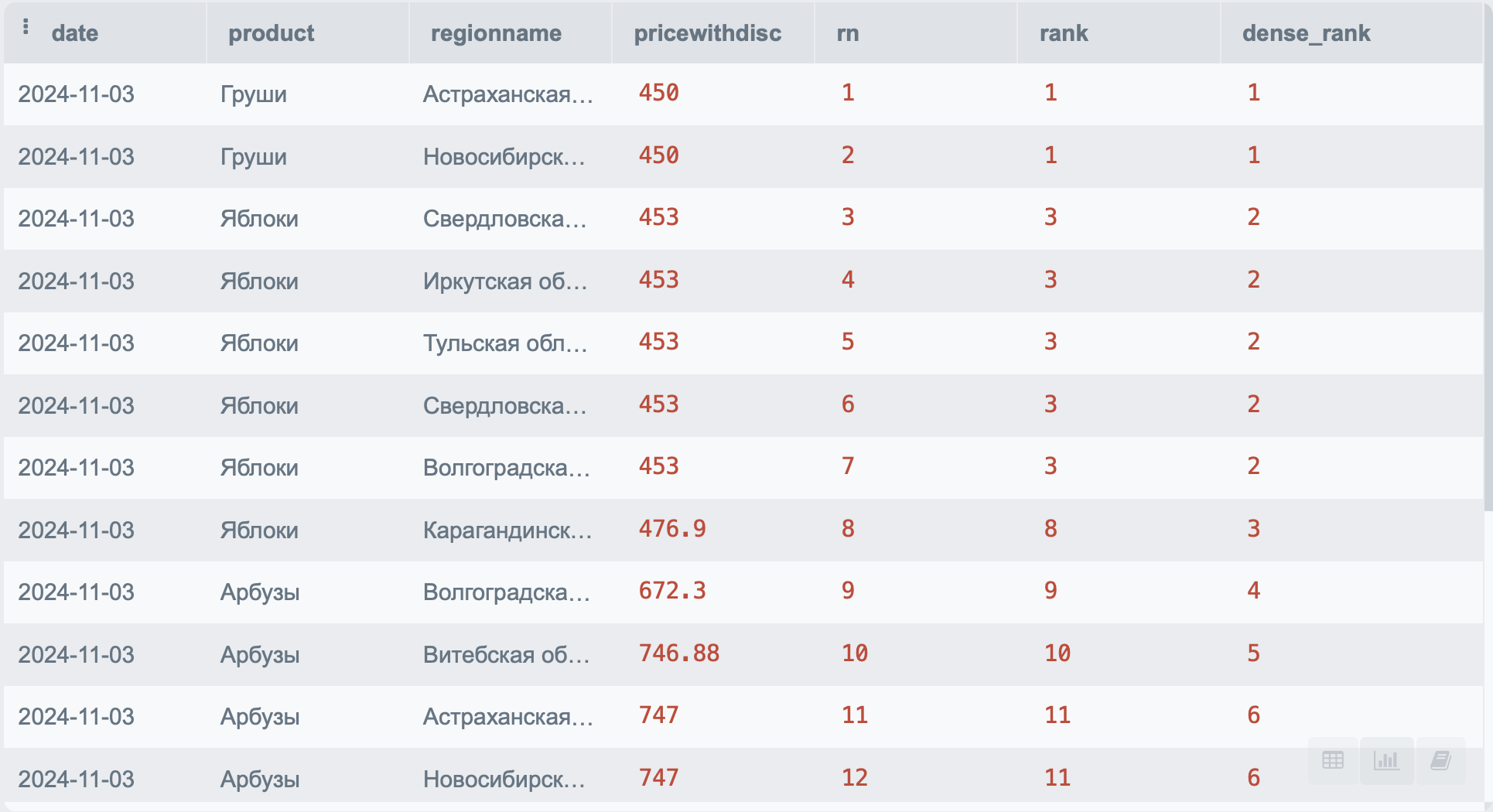
К этому виду оконных функций относятся RANK (функция позволяет определить ранг каждой строки, но при наличии двух одинаковых значений устанавливает одинаковый ранг), DENSE_RANK (выполняет ту же самую функцию, что и RANK, но при появлении двух одинаковых значений не пропускает значение) и ROW_NUMBER (определяет номер строки по заданным условиям).
Если говорить о моем опыте, то ROW_NUMBER – это самая часто используемая мной оконная функция. Она помогает быстро и эффективно избавиться от дублей, которые не всегда удается убрать DISTINCT'ом.
Давайте вернемся к нашему примеру и рассчитаем для него все три функции:
SELECT p.*,
ROW_NUMBER() OVER(ORDER BY pricewithdisc) as rn,
RANK() OVER(ORDER BY pricewithdisc) as rank,
DENSE_RANK() OVER(ORDER BY pricewithdisc) as dense_rank
FROM PRODUCT p
В итоге мы получим следующий результат:
Функции смещения
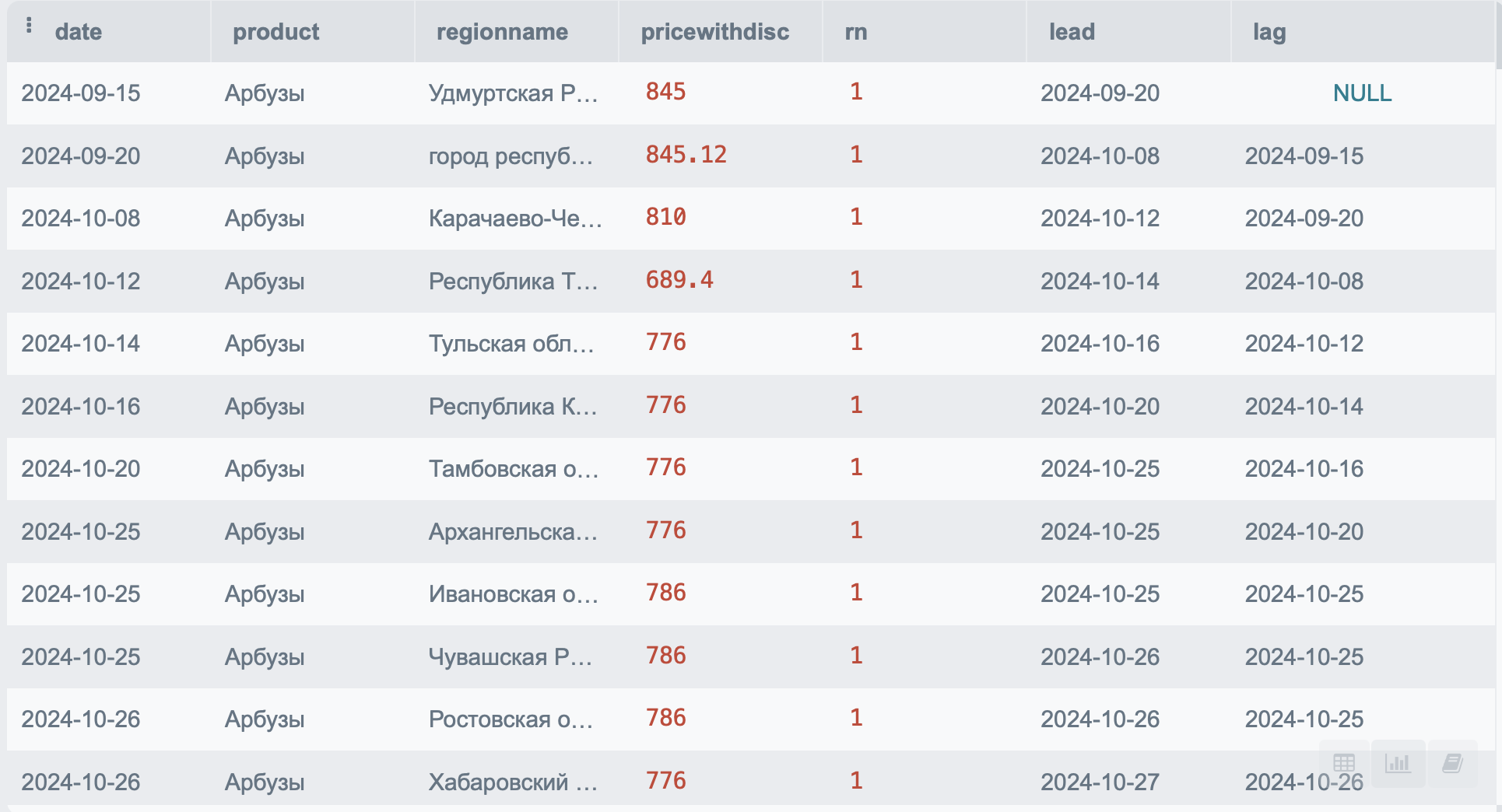
Функций смещения всего две - к ним относятся LEAD (поднимает наверх) и LAG (опускает вниз). Они позволяют сместить определенное значение на строку вверх или вниз. Обычно это применимо, когда вам нужно найти срок начала и окончания какого-либо периода, но у вас нет срока окончания. Вместо него вы можете взять срок следующего начала.
Давайте попробуем применить эти функции к нашей таблице:
SELECT p.*,
LEAD(date) OVER(PARTITION BY product order by date) as lead,
LAG(date) OVER(PARTITION BY product order by date) as lag
FROM PRODUCT p
Благодаря этим функциям во можете увидеть, что между первой и второй продажей прошло 5 дней.
Индексные функции
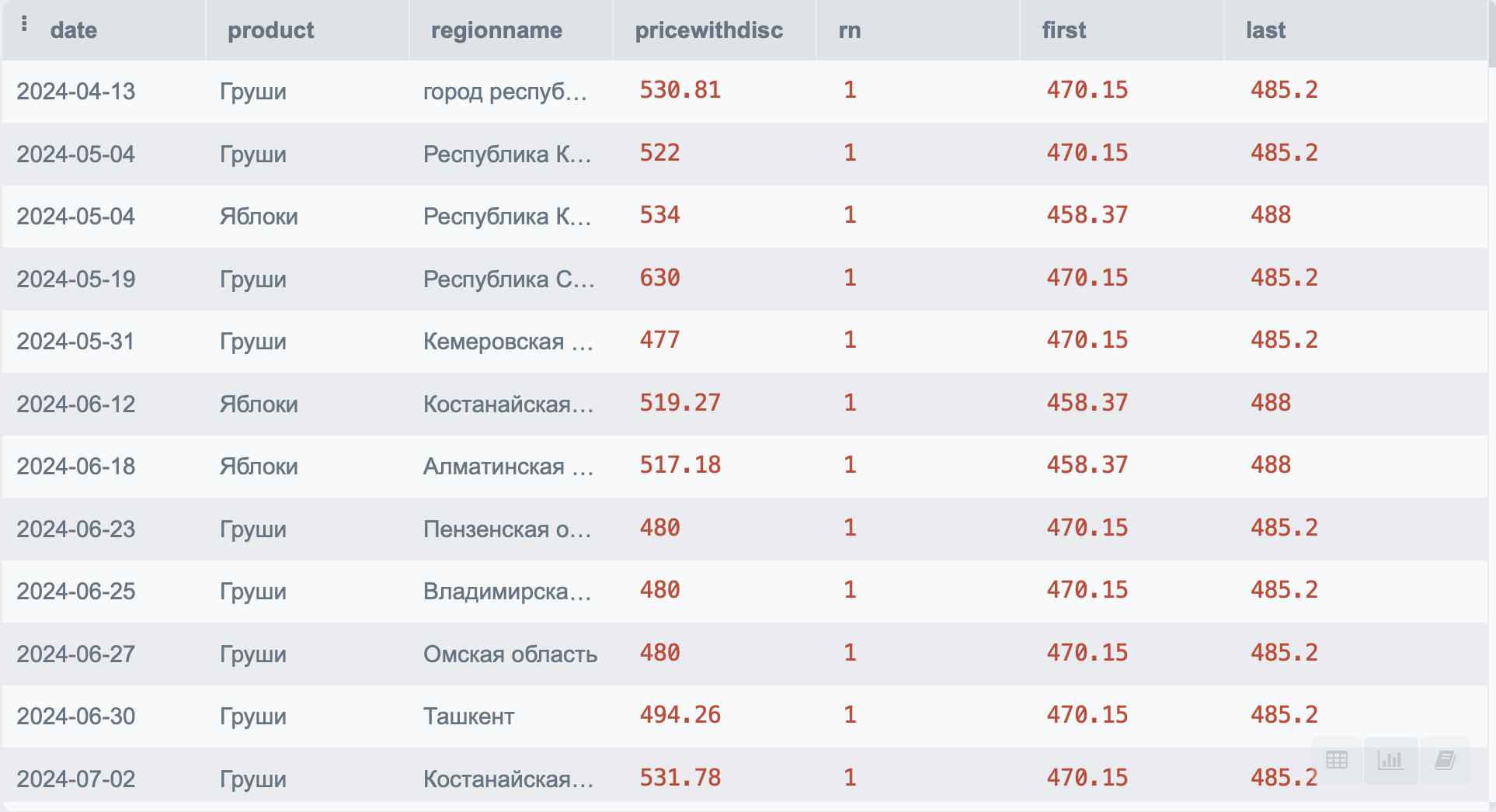
К этим функциям относятся FIRST_VALUE и LAST_VALUE, которые позволяют определить первое и последнее значение внутри окна, соответственно.
Например:
SELECT p.*,
FIRST_VALUE(pricewithdisc) OVER(PARTITION BY product) as first,
LAST_VALUE(pricewithdisc) OVER(PARTITION BY product) as last
FROM PRODUCT p
Данный пример равносилен поиску минимальной и максимальной цены по продукту, но это не значит, что функции бесполезны. Их тоже часто применяют для дедупликации данных.
Аналитические функции
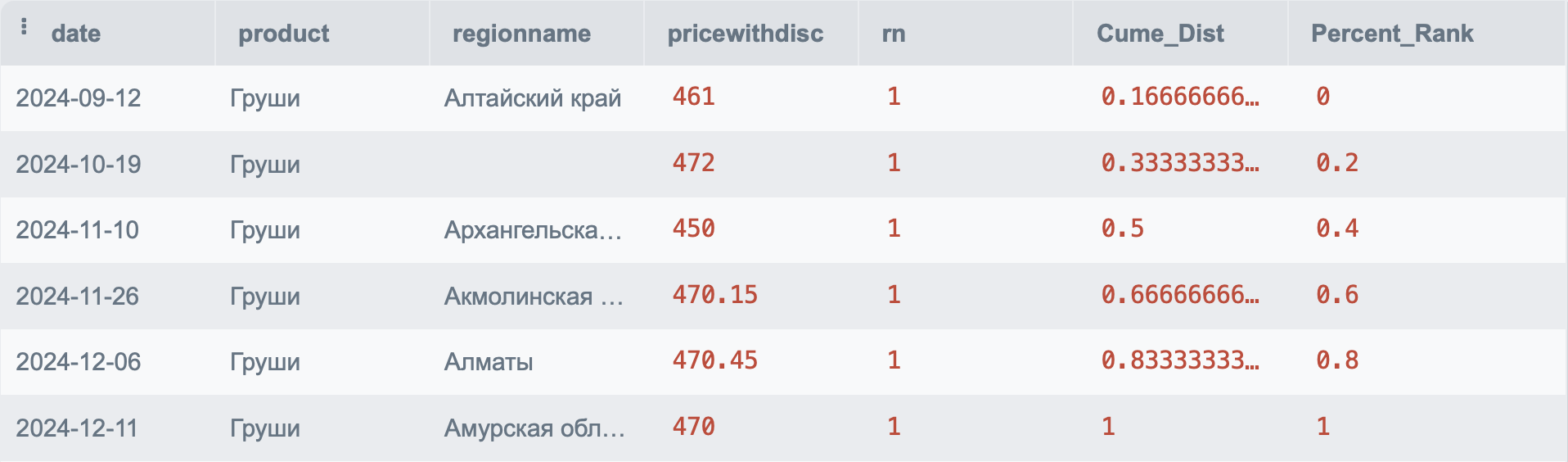
Аналитические оконные функции необходимы для получения информации о распределении данных внутри окна (партиции). К таким функциям относят: CUME_DIST (функция, необходимая для получения относительного положения строки внутри партиции) и PERCENT_RANK (для получения относительного ранга внутри партиции).
Пишутся они следующим образом:
SELECT p.*,
CUME_DIST() OVER(PARTITION BY product ORDER BY date) AS Cume_Dist,
PERCENT_RANK() OVER(PARTITION BY product ORDER BY date) AS Percent_Rank
FROM PRODUCT p
В результате мы получим следующие данные:
Функции бакетирования
К этой группе относится всего одна функция: NTILE. Она позволяет поделить массив данных на бакеты (группы), в зависимости от поставленных условий.
Например, перед вами стоит задача поделить данные на 4 равные группы по стоимости по убыванию. Сделать это можно следующим образом:
SELECT p.*,
NTILE(4) OVER(PARTITION BY product ORDER BY pricewithdisc DESC) as bucket
FROM PRODUCT p
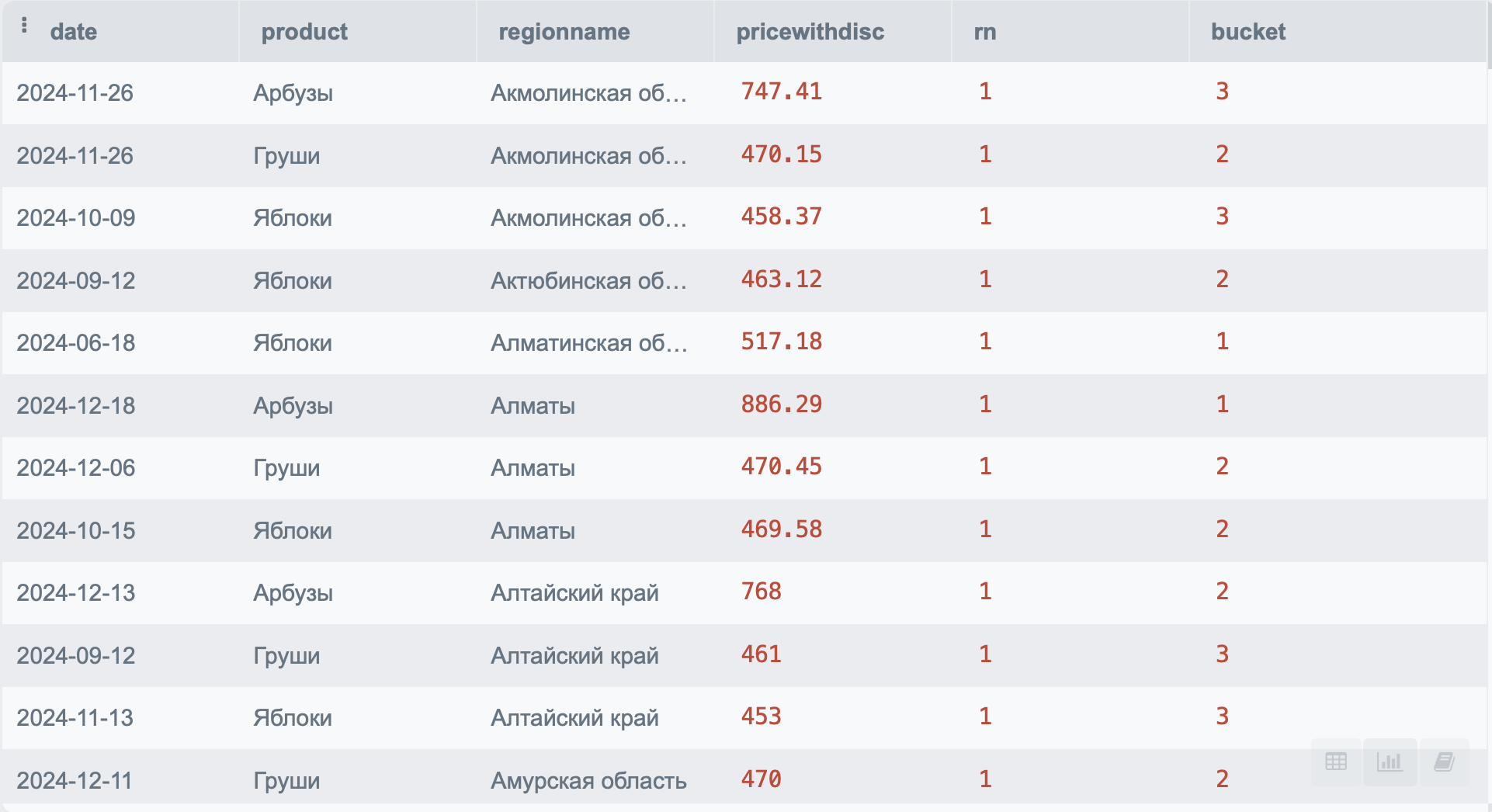
Эта функция полезна, когда вам необходимо разделить данные на 2 и более групп для проведения А/Б тестирования.
Функции конкатенации
Эта функция позволяет указать данные через запятую. Это может понадобиться, например, когда вам нужно указать номера телефонов одного клиента чтобы не замножать строки.
SELECT p.*,
group_concat(product, ',') OVER(ORDER BY date) as gc
FROM PRODUCT p
Эта функция позволяет указать данные через запятую или любой другой разделитель. Вот как это выглядит:
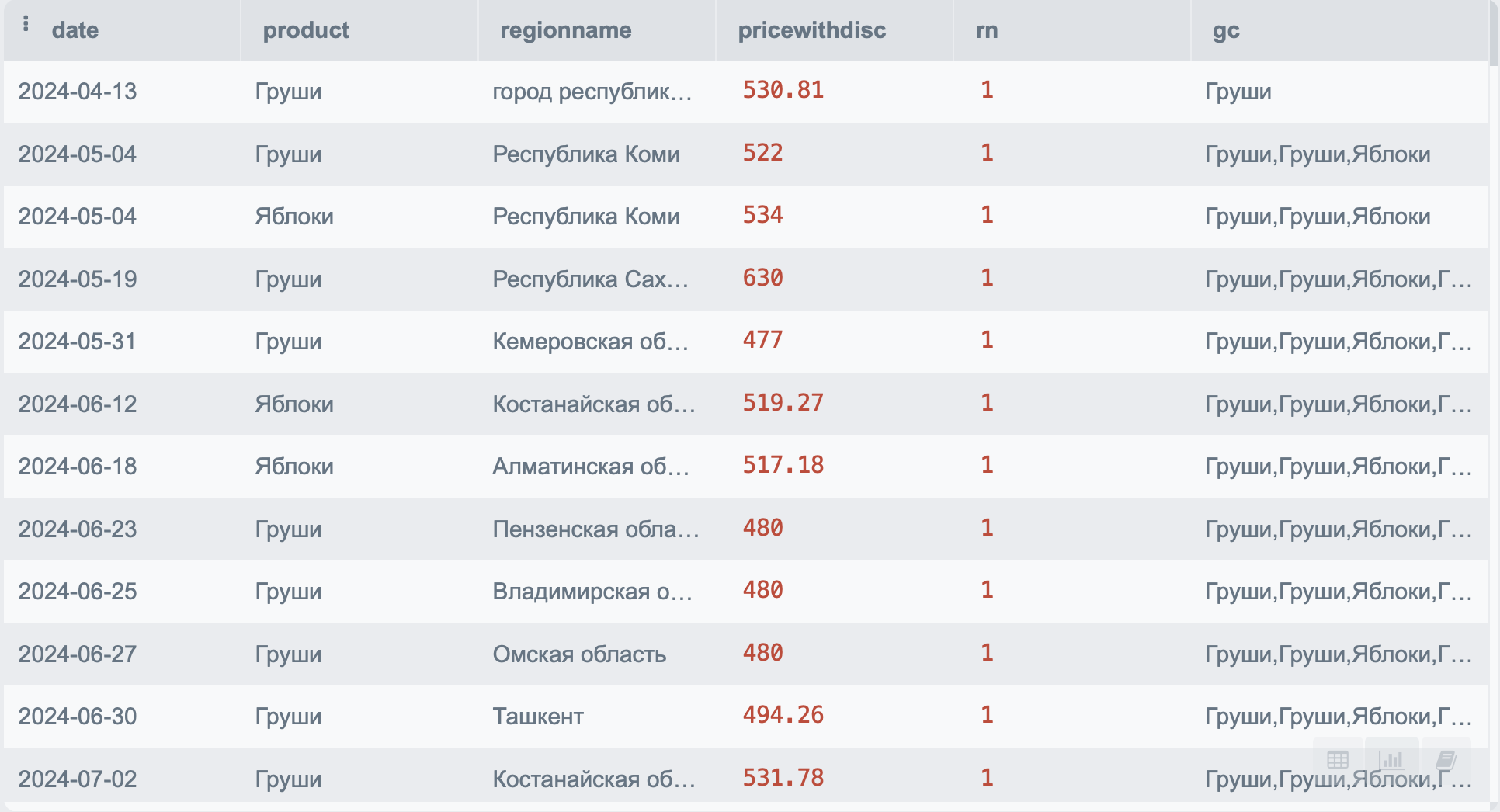
Использование ROWS
ROWS является очень полезным дополнением к оконным функциям. Благодаря нему можно указать диапазон строк. Например:
SELECT p.*,
sum(pricewithdisc) OVER(PARTITION BY product ROWS BETWEEN 1 PRECEDING AND 1 FOLLOWING) as s
FROM PRODUCT p
В данном примере мы посчитали сумму продаж в рублях по продукту, суммирую строки с предыдущей до последующей относительно строки расчета. То есть для первой строки мы сложили первую и вторую, для второй – первую, вторую и третью, для третьей – вторую, третью и четвертую и так далее.
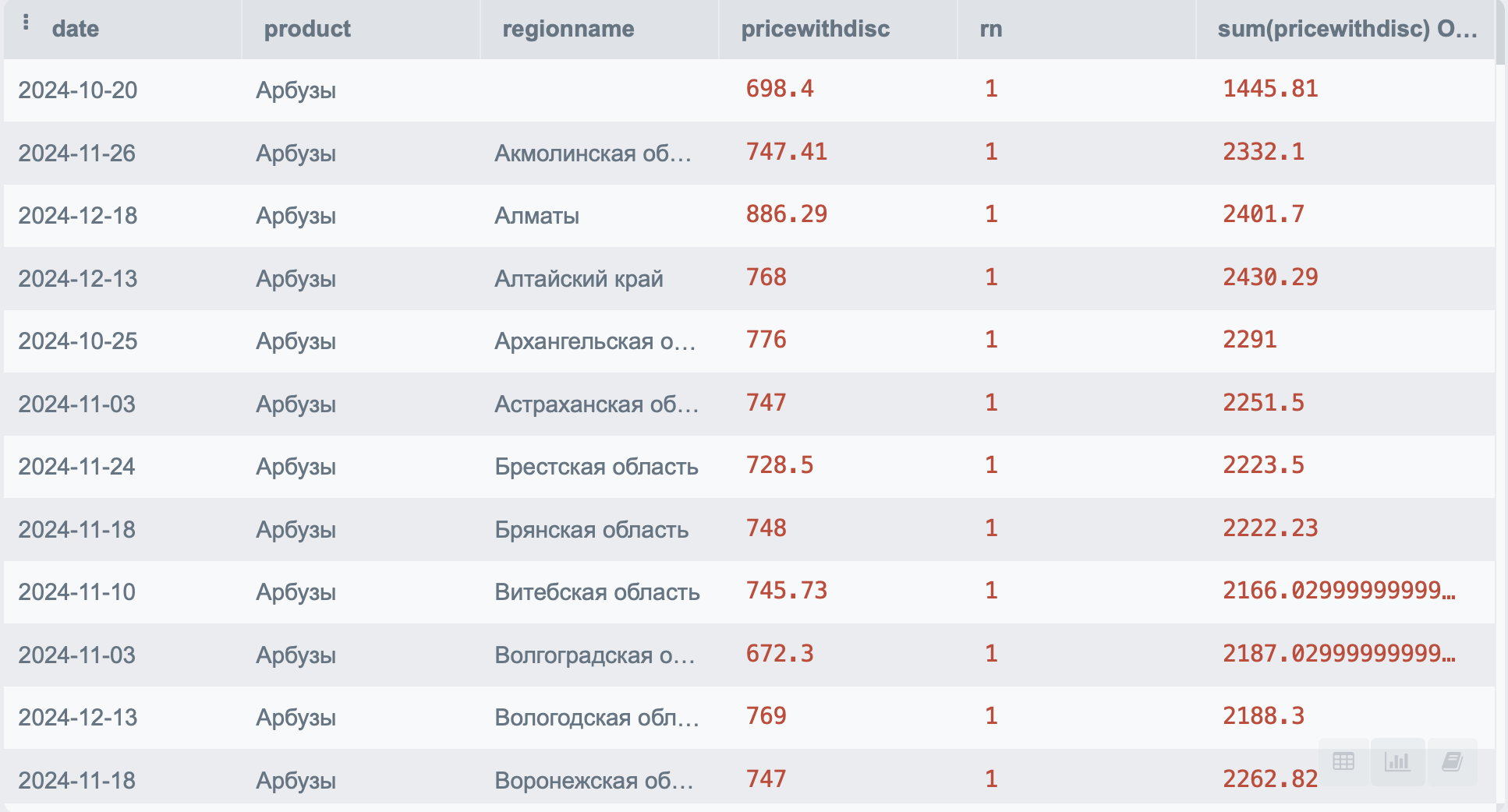
Вместо 1 FOLLOWING можно указать, например CURRENT ROW, тогда расчет будет производиться от предыдущей строки до текущей.
Использование агрегации внутри оконной функции
Также внутри оконных функций можно использовать агрегацию. Например, нам нужно указать ранг продукта в зависимости от количества продаж. Сделать это можно следующим образом:
SELECT p.product, COUNT(product),
RANK() OVER(ORDER BY COUNT(product) DESC) as rank
FROM PRODUCT p
GROUP BY product
В результате мы получим следующую картину:

Использование фильтрации внутри оконной функции
Очень часто бывает, что не хватает возможности фильтрации внутри оконной функции. Многие об этом не знают, но это возможно, если использовать вот такую конструкцию:
SELECT product, count(product) as cnt,
COUNT(product) FILTER(WHERE pricewithdisc >= 480) as cnt_where
FROM PRODUCT p
GROUP BY product
Получим вот такой результат:

Заключение
До недавнего времени, оконных функций не существовало и можно быть работать без них. Но их появление значительно упростило жизнь аналитиков. Оконные функции позволяют не только упросить проведение необходимых расчетов, но также помогают сделать код более читабельным и гибким.
Возможно, на первый взгляд, покажется, что оконные функции сложны, но как только вы напишите их несколько раз, то поймете насколько они удобны.